实例1
需求背景
我写文章使用的是支持markdown语法的typora,但是我在把文章上传到公众号平台时,文章中的图片总是上传失败(原因就是我的文章中图片的图床与公众号连接的线路不好,在从我的图床上传图片到公众号时,对超过一定时间还没有上传成功的图片就会直接上传失败)。
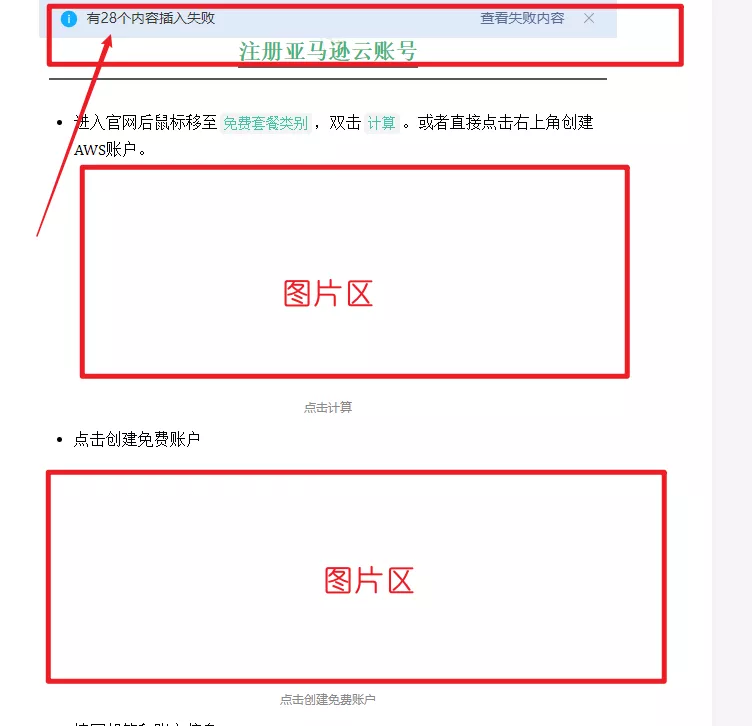
如上图,一共有29张图片其中28张图片插入失败。所以,我需要手动回到typora文件逐个把图片下载下来并且以阿拉伯数字从小到大排序,再按照顺上传到文章对应位置。
部分提问截图
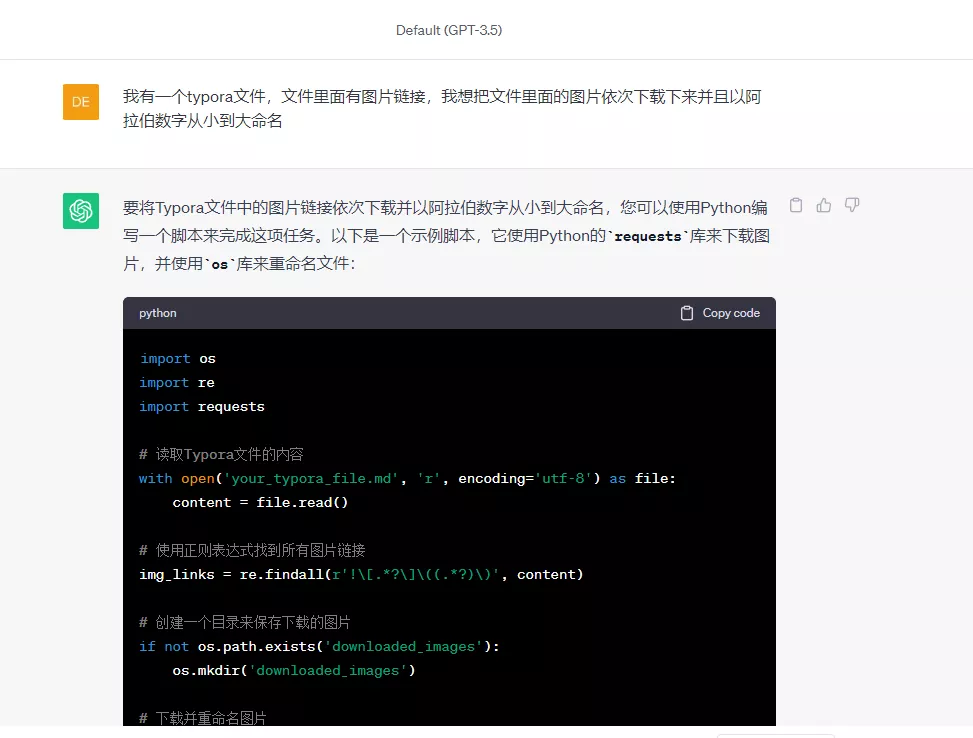
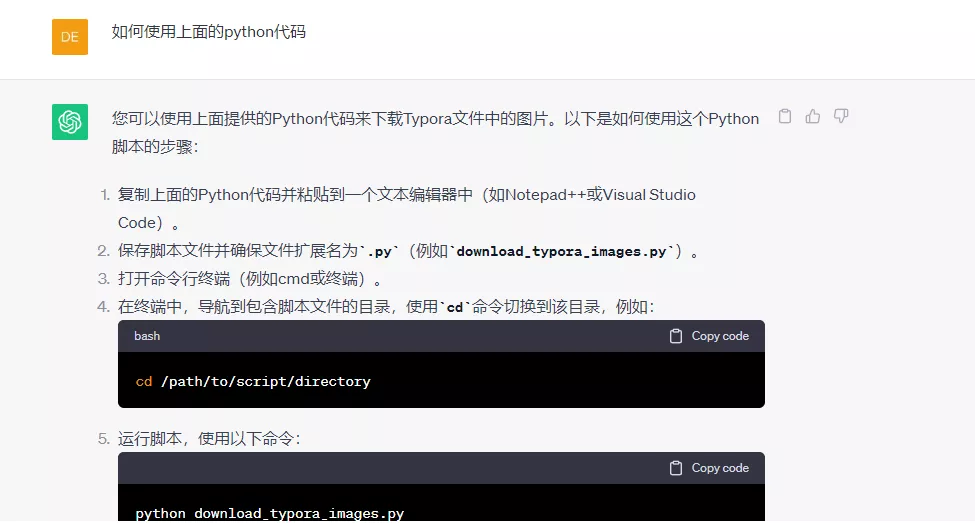
补充一句:使用chatgpt提问时,要把它当作一个人来交流,要把自己的需求表达的完善充足,它回答的对要给予它肯定,错误也要指出,这样不断地训练它纠正它,它给出的答案就越准确。使用chatgpt的一个误区就是把它当成普通的搜索引擎使用!!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| import os
import re
import requests
from tkinter import filedialog
import tkinter as tk
root = tk.Tk()
root.withdraw()
typora_file_path = filedialog.askopenfilename(title="选择 Typora 文件", filetypes=[("Markdown 文件", "*.md")])
if not typora_file_path:
print("未选择文件,退出...")
exit()
with open(typora_file_path, 'r', encoding='utf-8') as file:
content = file.read()
img_links = re.findall(r'!\[.*?\]\((.*?)\)', content)
if not os.path.exists('downloaded_images'):
os.mkdir('downloaded_images')
for i, img_link in enumerate(img_links):
response = requests.get(img_link)
if response.status_code == 200:
file_extension = os.path.splitext(img_link)[-1]
new_filename = f'downloaded_images/{i + 1}{file_extension}'
with open(new_filename, 'wb') as img_file:
img_file.write(response.content)
print(f'下载成功: {new_filename}')
else:
print(f'下载失败: {img_link}')
print('图片下载完成。')
|
功能是从用户选定的 Typora 文件中提取 Markdown 格式的图片链接,并下载这些图片到本地目录。
确保已安装所需的Python库,可以使用以下命令安装:
您可以使用上面提供的Python代码来下载Typora文件中的图片。以下是如何使用这个Python脚本的步骤:
复制上面的Python代码并粘贴到一个文本编辑器中(如Notepad++或Visual Studio Code)。
保存脚本文件并确保文件扩展名为.py(例如download_typora_images.py)。
打开命令行终端(例如cmd或终端)。
在终端中,导航到包含脚本文件的目录,使用cd命令切换到该目录,例如:
1
| cd /path/to/script/directory
|
运行脚本,使用以下命令:
1
| python download_typora_images.py
|
确保您已安装了Python,并且python命令可以在命令行中正常运行。
脚本将开始执行,根据Typora文件中的图片链接下载图片,并将它们以阿拉伯数字从小到大命名,保存在名为downloaded_images的文件夹中。
请注意,脚本执行完成后,您将在脚本文件的目录中看到一个名为downloaded_images的文件夹,其中包含下载的图片。确保在运行脚本之前备份Typora文件,以防万一。
实例2
需求背景:hexo的_post文章目录下有50多个.md格式的文件,文件里面有图床图片链接,由于图床的域名需要更换,所以所有文件里面存在之前图床域名的图片都要替换成现在的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
| import os
import tkinter as tk
from tkinter import filedialog, messagebox
from tkinter.simpledialog import Dialog
import re
class SearchReplaceDialog(Dialog):
def __init__(self, parent):
self.search_text = ""
self.replace_text = ""
self.use_regex = False
super().__init__(parent, title="查找和替换")
def body(self, master):
tk.Label(master, text="查找文本:").grid(row=0)
tk.Label(master, text="替换文本:").grid(row=1)
self.search_entry = tk.Entry(master)
self.replace_entry = tk.Entry(master)
self.search_entry.grid(row=0, column=1)
self.replace_entry.grid(row=1, column=1)
self.mode_var = tk.BooleanVar(value=False)
tk.Radiobutton(master, text="全局替换", variable=self.mode_var, value=False).grid(row=2, column=0, columnspan=2)
tk.Radiobutton(master, text="正则表达式", variable=self.mode_var, value=True).grid(row=2, column=1, columnspan=2)
return self.search_entry
def apply(self):
self.search_text = self.search_entry.get()
self.replace_text = self.replace_entry.get()
self.use_regex = self.mode_var.get()
def main():
root = tk.Tk()
root.withdraw()
folder_path = filedialog.askdirectory(title="请选择文件夹")
if not folder_path:
print("未选择文件夹,操作取消。")
return
dialog = SearchReplaceDialog(root)
search_text = dialog.search_text
replace_text = dialog.replace_text
use_regex = dialog.use_regex
if not search_text or not replace_text:
print("查找或替换文本为空,操作取消。")
return
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.endswith(".md"):
file_path = os.path.join(root, file)
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
if use_regex:
new_content = re.sub(search_text, replace_text, content)
else:
new_content = content.replace(search_text, replace_text)
if content != new_content:
with open(file_path, 'w', encoding='utf-8') as f:
f.write(new_content)
print(f"替换成功:{file_path}")
else:
print(f"未发现替换内容:{file_path}")
print("替换操作完成!")
if __name__ == "__main__":
main()
|
代码功能:可以用于批量查找和替换 Markdown 文件内容








